Data Lakes: All You Need to Know
Data lakes are centralized storage repositories. This burgeoning technology is gaining traction for big data storage. Here's all you need you to know.
Join the DZone community and get the full member experience.
Join For FreeEvery organization in the modern world relies on data to capitalize on opportunities, solve business challenges, and make informed decisions for their business. However, with the increasing volume, variety, and velocity of data generated, companies in every industry are continuously seeking innovative solutions for storing, processing, and managing their data. Various technologies are being developed to support the big data revolution and address common challenges in data management.
One such burgeoning technology, and a buzzword in today’s world where data is the ultimate foundation of business, is data lakes. This article provides more details about data lakes by explaining what they are and their importance. You will also learn more about the data lake architecture and the key best practices for deploying data lakes.
What Is a Data Lake?
A data lake is a centralized storage repository that stores a vast amount of data in its native form. It can hold structured data from the traditional relational databases, semi-structured data such as JSON and CSV, as well as unstructured raw data such as images, videos, audio, binary files, text, and more.
At a high level, data lakes leverage the concept of object storage and open data formats. The primary objective of the shared data storage is to provide a centralized source of all enterprise data. It is consolidated in such a way that each of the data types can be collectively analyzed or transformed without having to pre-impose a structure or schema on it.
A data lake can be built on-premises or in the cloud, with trend currently pointing to the latter because users can leverage its unlimited power, flexibility, and scalability. Whether deployed on-premises or in the cloud, data lakes can are characterized by three basic attributes, namely:
- Collect everything: Data lakes contain both raw sources of data as well as processed data, usually collected over an extended period.
- Flexible access: Data lakes support multiple patterns for accessing data held in the shared infrastructure.
- Dive in anywhere: Users across different business units can explore, refine, and enrich data stored in a data lake.
The Importance of Data Lakes
Most companies have tons of business data usually siloed away and isolated in a wide range of storage systems including databases and data warehouses. To make the best out of these data assets, you should centralize and consolidate the data into a unified data store for enhanced analytics.
Through the data lake architecture, organizations can streamline cross-functional enterprise analytics at an even higher scale. The ability to query the data lake and harvest rich insights brings massive business value. When properly built and deployed, a data lake gives you the ability to:
- Centralize, consolidate, and catalog business data, thereby eliminating problems associated with data silos
- Integrate a wide range of data sources and formats in a seamless manner
- Power data science and leverage machine learning
- Democratize enterprise data by providing self-service tools to multiple users.
Data Lake Architecture
Below is a high-level diagram that summarizes the data lake architecture. It also shows the components of each block in the architecture for your understanding.
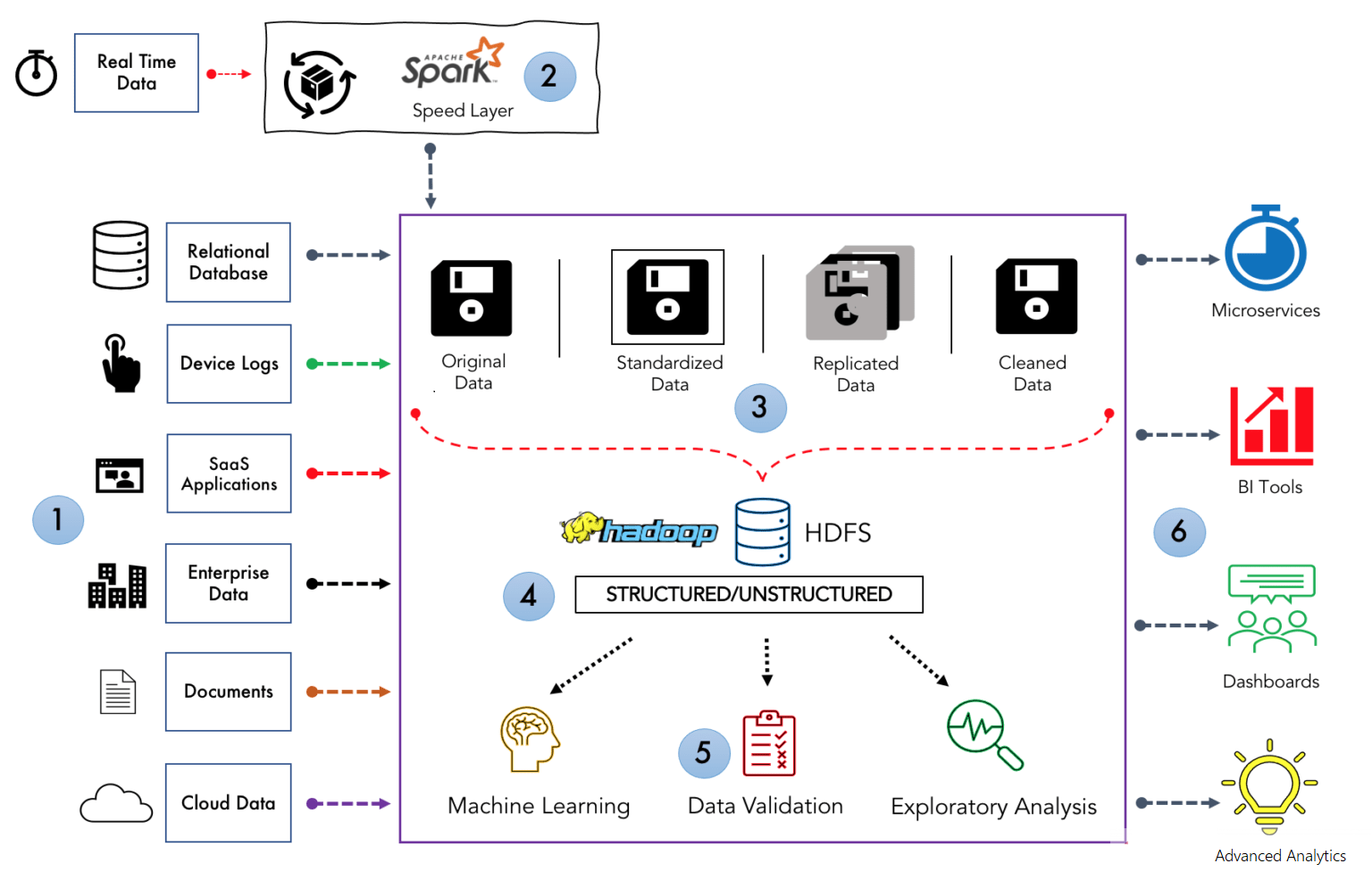
The following is a brief description of components 1 to 6 of the data lake architecture.
- Data sources: there is a wide range of structured and unstructured data sources that feed into the data lake. These include relational databases, device logs, enterprise data, SaaS data, documents, social media, cloud data, and many more.
- Data batch processing: as mentioned previously, data lakes hold all types of data assets, most of which are not produced in real-time. As such, most data loaded into a data lake is stored in batch format. A real-time data framework like lambda architecture or Kafka Streams is used for stream processing before data is placed in the lake.
- Data ingestion: although a data lake is a unified central repository for holding data, this data is not loaded into the data lake without any cleansing or processing. A number of processes are implemented to ensure every piece of data is in proper shape before it is moved to the next pipeline. This involves transforming it into consumable data-set sizes and ensuring it is in a better structure for easier analysis.
- Data storage: as the name implies, this is where data the different types of data are stored. Tools like Hadoop and Cassandra are used for storage purposes.
- Data analysis: data lakes allow various teams in an enterprise to access the data using analytical tools and frameworks of their choice. Analysts can make use of this data without moving it into separate storage for processing, analyzing, refining, or transforming.
- Reporting: data lakes are connected to modern business intelligence tools such as Apache Superset, Metabase, or tableau for preparing the data for analysis and building reports.
Data Lake vs. Data Warehouse
Although the data lake architecture is becoming increasingly popular in recent years, there are many IT practitioners out there who still do not have a clear idea about data lakes. Some argue that a data lake is simply a reincarnation of a data warehouse. At the same time, others are a bit skeptical about data lakes, often warning users not to go in since it might be a swamp. To clear the air, we will put together the main differences between a data lake and a data warehouse. But before that, what is a data warehouse?
A data warehouse is used for storing highly organized and structured data. Every piece of data that is loaded into the warehouse must be defined and its use identified. This means that when developing a warehouse, a significant amount of time and effort goes to analyzing data sources, understanding business processes, and refining the data to include.
Below is a summary of the main differences between a data lake and a data warehouse.
Conclusion
Data lakes are extremely powerful for businesses that want to store multiple types of data and derive immense value from their data assets. However, as we have seen in the data lake architecture, there is much more that goes into building data lakes than just the data. You need a way to build proper security features and access controls into your data lake. Additionally, you must interface the data lake with the right tools to make it more accessible.
Feature Photo by Michael Dziedzic on Unsplash
Opinions expressed by DZone contributors are their own.
Comments