Data Management in Distributed Systems: A Comprehensive Exploration of Open Table Formats
This article emphasizes the revolutionary effect of open table formats on data management practices in distributed computing landscapes.
Join the DZone community and get the full member experience.
Join For FreeOpen table formats are file formats tailored to store vast datasets in distributed data processing systems. They streamline data storage with features like:
- Columnar storage for analytical workloads
- Compression for reduced storage costs and improved performance
- Schema evolution for adapting to changing data structures
- ACID compliance, ensuring data integrity
- Support for transactional operations
- Time travel capabilities for historical data querying
- Seamless integration with various data processing frameworks and ecosystems
These characteristics collectively enable the construction of scalable, dependable, and efficient data processing pipelines, making open table formats preferred options in contemporary data architectures and analytics workflows.
Let us dive deep into the open table formats Apache Iceberg, Apachi Hudi, and Delta Lake.
Apache Iceberg
Apache Iceberg is an open-source table format designed for large-scale data lakes, aiming to improve data reliability, performance, and scalability. Its architecture introduces several key components and concepts that address the challenges commonly associated with big data processing and analytics, such as managing large datasets, schema evolution, efficient querying, and ensuring transactional integrity. Here's a deep dive into the core components and architectural design of Apache Iceberg:

Figure 1: Apache Iceberg architecture (Source: Dremio)
1. Table Format and Metadata Management
Versioned Metadata
Iceberg uses a versioned metadata management system where each operation on a table creates a new snapshot of the table metadata. This approach ensures atomicity and consistency, supporting ACID transactions, whether changes are fully applied or not.
Snapshot Management
Each snapshot contains full table metadata, including schema information, partitioning details, and file lists. Snapshots enable time travel capabilities, allowing users to query data as it was at any point in time.
Metadata Files
Metadata is stored in JSON format, making it easily readable and accessible. The use of lightweight metadata files also simplifies operations like schema evolution and partitioning changes, as these operations only require metadata updates without affecting the actual data.
2. File Organization and Partitioning
Partitioning
Iceberg introduces a flexible partitioning system that supports partition evolution. Partitions are defined in the table metadata, allowing for changes over time without the need to rewrite data. This significantly reduces the complexity of managing evolving datasets.
File Layout
Data is organized into files stored in object storage. Iceberg supports multiple file formats, including Parquet, Avro, and ORC. Files are grouped into "manifests" for efficient metadata management.
Hidden Partitioning
Iceberg's partitioning is logical and decoupled from the physical storage, enabling optimizations like predicate pushdown for efficient data access without the need for costly directory traversals.
3. Scalability and Performance
Incremental Processing
Iceberg tables are designed for efficient incremental data processing. By tracking additions and deletions in snapshots, Iceberg enables consumers to process only the changes between snapshots, reducing the amount of data to scan.
Scalable Metadata Operations
The architecture is designed to scale metadata operations, allowing for efficient handling of large datasets. The use of compact metadata files and manifest lists helps in managing extensive datasets without performance degradation.
4. Query Engine Integration
Broad Ecosystem Support
Iceberg is designed to integrate seamlessly with a wide range of query engines and data processing frameworks, including Apache Spark, Trino, Flink, and Hive. This is achieved through a well-defined API that allows these engines to leverage Iceberg's features like snapshot isolation, schema evolution, and efficient file pruning.
5. Transaction Support and Concurrency
ACID Transactions
Iceberg provides ACID transactions to ensure data integrity, supporting concurrent reads and writes. The optimistic concurrency model allows multiple operations to proceed in parallel, with conflict detection and resolution mechanisms in place to maintain consistency.
6. Schema Evolution and Compatibility
Schema Evolution
Iceberg supports adding, renaming, deleting, and updating columns while maintaining backward and forward compatibility. This allows for schema changes without downtime or data migration.
Apache Iceberg's architecture is designed to address the limitations of traditional data lakes by providing reliable ACID transactions, efficient metadata management, and scalable data processing capabilities. Its flexible partitioning, versioned metadata, and integration with popular query engines make it a robust solution for managing large-scale data lakes in a variety of use cases, from analytical workloads to real-time streaming.
Apache Hudi
Apache Hudi (short for Hadoop Upserts Deletes and Incrementals) is an open-source data management framework used to simplify incremental data processing and data pipeline development on top of data lakes like HDFS, S3, or cloud-native data services. Hudi brings stream processing to big data, providing fresh data while also efficiently storing large datasets. Here's a deep dive into the architecture and core components of Apache Hudi:
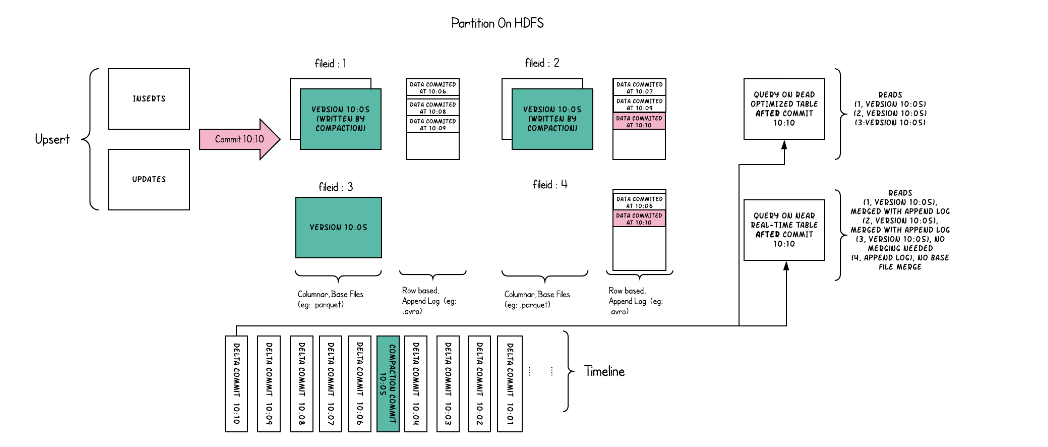
Figure 2: Apache Hudi architecture (Source)
1. Core Concepts
Table Types
Hudi supports two types of tables: Copy on Write (CoW) and Merge on Read (MoR). CoW tables are optimized for read-heavy workloads with simpler write patterns, where each write operation creates a new version of files. MoR tables support more complex workloads with frequent reads and writes, storing data in a combination of columnar (for efficient reading) and row-based formats (for efficient upserts).
Record Keys and Partitioning
Hudi tables are indexed by a record key, and data is partitioned into directories on the file system based on a partition path. This structure enables efficient upserts (updates and inserts) and deletes.
2. Data Storage and Management
File Size Management
Hudi automatically manages file sizes and layouts to optimize read and write performance. It compacts small files and organizes data into larger ones to improve efficiency.
Indexing
Hudi maintains indexes to quickly locate records for updates or deletes, significantly reducing the amount of data that needs to be scanned during such operations.
Log Files for MoR Tables
In Merge on Read tables, Hudi uses log files to store incoming writes (upserts and deletes) efficiently. This allows for quicker writes, deferring the merging of data into columnar files until read or compaction time.
3. Transactions and Concurrency
ACID Transactions
Hudi provides snapshot isolation for reads and writes, enabling transactions. This ensures data integrity and consistency even in the presence of concurrent operations.
Optimistic Concurrency Control
Hudi employs optimistic concurrency control to manage concurrent writes. It resolves conflicts by retrying or failing operations, depending on the conflict resolution strategy.
4. Incremental Processing
Change Capture and Incremental Pulls
Hudi supports capturing changes to data at the record level, enabling efficient incremental data processing. Applications can query for data changes at a specific point in time, reducing the amount of data to process.
5. Query Engine Integration
Wide Compatibility
Hudi integrates with popular query engines like Apache Spark, Apache Flink, Presto, and Hive. This allows users to query Hudi tables using familiar tools and APIs.
6. Scalability and Performance
Scalable Metadata Management
Hudi is designed to handle large datasets by efficiently managing metadata. It leverages compact, serialized metadata formats and scalable indexing mechanisms to maintain performance.
Data Compaction
For Merge on Read tables, Hudi performs background compaction of log files into columnar formats, optimizing read performance without impacting ongoing writes.
7. Data Management Features
Time Travel
Hudi supports querying data as of a specific point in time, enabling time travel queries for auditing or rollback purposes.
Schema Evolution
Hudi handles schema changes gracefully, allowing for additions, deletions, and modifications of table schema without disrupting data processing.
Apache Hudi's architecture is designed to address the complexities of managing large-scale data lakes by providing efficient upserts, deletes, and incremental processing capabilities. Its integration with popular big data processing frameworks, ACID transaction support, and optimizations for both read and write performance make it a powerful tool for building high-throughput, scalable data pipelines. Hudi's approach to data management enables faster data refreshes and simplifies handling late-arriving data, making it an essential component in modern data architecture for real-time analytics and data processing.
Delta Lake Architecture
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads, designed to provide a more reliable and performant data lake. Delta Lake enables users to build robust data pipelines that are resilient to failures, support concurrent reads and writes, and allow for complex data transformations and analytics. Here's a deep dive into the core components and architectural design of Delta Lake:

Figure 3: Delta Table (Source: Delta Lake Documentation)
1. Core Concepts and Components
ACID Transactions
Delta Lake ensures data integrity and consistency across reads and writes by implementing ACID transactions. This is achieved through atomic operations on the data, which are logged in a transaction log, ensuring that each operation either fully completes or does not happen at all.
Delta Table
A Delta table is a versioned parquet table with a transaction log. The transaction log is a record of every change made to the table and is used to ensure consistency and enable features like time travel.
Schema Enforcement and Evolution
Delta Lake enforces schema validation on write operations, preventing bad data from causing data corruption. It also supports schema evolution, allowing for the addition of new columns and changes to the table schema without breaking existing queries.
2. Transaction Log
The transaction log (often referred to as the Delta Log) is a key component of Delta Lake's architecture. It contains JSON files that track changes to the table, including information about commits, saved as ordered, and immutable log entries. This log allows Delta Lake to:
- Maintain a timeline: Track all transactions and modifications to the table, supporting atomicity and consistency.
- Support time travel: Query previous versions of the table, enabling data rollback and auditing.
- Enable concurrency: Manage concurrent reads and writes efficiently using optimistic concurrency control.
3. Data Storage and Management
Parquet Files
Delta Lake stores data in Parquet files, leveraging its efficient, columnar storage format. Parquet files are immutable, and modifications create new versions of files, which are then tracked through the transaction log.
File Management
Delta Lake optimizes file storage by compacting small files and coalescing them into larger ones to improve read performance. It also supports partitioning to enhance query performance.
4. Scalability and Performance
Optimized Layouts
Delta Lake uses Z-ordering and data skipping to optimize the layout of data on disk, significantly reducing the amount of data scanned for queries.
Streaming and Batch Processing
Seamlessly integrate streaming and batch data processing within the same pipeline, ensuring that data is up-to-date and consistent across all operations.
5. Advanced Data Operations
Upserts, Deletes, and Merges
Delta Lake supports advanced data operations like upserts (MERGE INTO), deletes, and merges, making it easier to manage and maintain data lakes by simplifying complex transformations and updates.
Incremental Processing
Delta Lake allows for efficient incremental processing of data changes, enabling the building of complex ETL pipelines that can process only the data that has changed since the last operation.
6. Integration With the Data Ecosystem
Delta Lake is deeply integrated with Apache Spark, and its APIs are designed to be used seamlessly with Spark DataFrames. This tight integration allows for high-performance data transformations and analytics. Additionally, Delta Lake can be used with other data processing and query engines, enhancing its versatility in a multi-tool data architecture.
Delta Lake's architecture addresses many of the challenges faced by data engineers and scientists working with big data, such as ensuring data integrity, supporting complex transactions, and optimizing query performance. By providing ACID transactions, scalable metadata handling, and robust data management features, Delta Lake enables more reliable and efficient data pipelines, making it a foundational component of modern data platforms.
Comparison Table Between Iceberg, Hudi, and Delta Lake
| Feature | Apache Iceberg | Apache Hudi | Delta Lake |
|---|---|---|---|
| Foundation | Open table format for huge analytic datasets | Data management framework for incremental processing | Storage layer that brings ACID transactions |
| Primary Use Case | Improving data reliability, performance, and scalability in data lakes | Simplifying data pipeline development on data lakes | Making big data workloads more reliable and performant |
| Data Structure | Table format with versioned metadata | Supports Copy on Write (CoW) and Merge on Read (MoR) tables | Versioned Parquet table with a transaction log |
| Schema Evolution | Supports adding, renaming, deleting, and updating columns | Handles schema changes, allowing additions, deletions, and modifications | Enforces schema validation and supports evolution |
| Partitioning | Flexible partitioning system with partition evolution | Indexed by record key, partitioned into directories | Supports partitioning, optimized through Z-ordering |
| ACID Transactions | Yes, with atomic operations and snapshot isolation | Yes, it provides snapshot isolation for reads and writes | Yes, it ensures data integrity across reads and writes |
| Concurrency and Conflict Resolution | Optimistic concurrency model | Optimistic concurrency control with conflict resolution | Manages concurrent reads and writes efficiently |
| Incremental Processing | Designed for efficient incremental data processing | Captures changes at the record level for efficient incremental pulls | Allows incremental processing of data changes |
| Time Travel | Snapshot management for querying data at any point in time | Snapshot management for querying data at any point in time | Time travel for data rollback and auditing |
| File Formats | Supports multiple formats like Parquet, Avro, ORC | Manages file sizes and layouts, compacting for efficiency | Stores data in Parquet files, optimizing file management |
| Query Engine Integration | Broad support (e.g., Apache Spark, Trino, Flink) | Compatible with popular query engines like Spark, Flink, Presto | Deeply integrated with Apache Spark |
| Performance Optimizations | Metadata management for large datasets, hidden partitioning | Scalable metadata and indexing, file size management | Optimizes layout with Z-ordering, data skipping |
| Operational Features | Supports upserts, deletes, and schema evolution with minimal impact on performance | Advanced data operations like upserts, deletes, merges | Advanced operations like upserts, deletes, merges |
Conclusion
Open table Formats, such as Apache Iceberg, Apache Hudi, and Delta Lake, represent a significant advancement in managing vast datasets within distributed data processing systems. These formats bring forth many features to enhance data storage, processing, and analysis in traditional significant data ecosystems like Apache Spark and Hadoop, and modern cloud-based data lakes. Key attributes include columnar storage optimization for analytical processing, data compression to minimize storage costs and boost performance, and schema evolution capabilities that adapt to changing data structures. Additionally, they ensure data integrity through ACID compliance, support transactional operations, offer time travel features for accessing historical data, and facilitate seamless integration across diverse data processing frameworks.
Opinions expressed by DZone contributors are their own.
Comments