Fine-Tuning Large Language Models on Custom Data
Let's gain a better understanding of how to make Large Language Models return the proper results with an approach known as fine-tuning.
Join the DZone community and get the full member experience.
Join For FreeLarge Language Models (LLMs) are advanced artificial intelligence systems designed to understand and generate natural language text. They are trained on extensive datasets of text from the internet including books, websites, and articles, allowing them to learn language patterns, grammar, and a wide range of information. As a result, LLMs generate coherent and contextually relevant text based on the input they receive.
LLMs are constantly evolving and learning new tricks, pushing the boundaries of what's possible with generative AI — and with great (AI) power comes great responsibility; the same goes with LLMs. Sometimes LLMs generate outputs that aren’t expected, fake, and not tuned properly. In this article, we will gain a better understanding of how to make LLMs return the proper results with an approach known as fine-tuning.
Challenges With LLMs
While LLMs boast impressive general language skills, directly applying them to specific tasks can be problematic. Their vast training data may lack domain-specific expertise, leading to inaccurate or irrelevant outputs. They often struggle with contextual understanding, misinterpreting prompts, or missing crucial information. Additionally, relying on black-box algorithms makes it difficult to control outputs — raising concerns about bias, misinformation, and even ethical implications.
Here's a deeper look into each limitation and how it impacts LLMs' effectiveness:
Tailored Outputs: Sometimes applications demand a specific type of style and structure as output but LLMs might not produce the tailored outputs required. This is where LLMs need proper tuning and training to understand styles so they can produce tailored outputs.
Missing Context: The base LLM models won't know domain-specific details are absent from their training data. Training LLMs by feeding specific details from the trusted sources is important.
Specialized Vocabulary: LLMs are generally trained on a general dataset and often fail to understand specialized vocabulary in fields like medicine, finance, or law. This leads to challenges in summarizing, interpreting, or discussing niche topics with accuracy, leading to generic or incorrect responses that significantly impede their utility in specialized sectors. This is where fine-tuning the LLMs becomes highly important.
Fine-tuning overcomes these limitations by specializing LLMs for specific tasks through targeted data and training, ultimately unlocking their true potential for accurate and reliable applications.
What Is Fine-Tuning?
Imagine LLMs as language experts with vast knowledge, but lacking specific skills. Fine-tuning acts like an apprenticeship, taking these experts and equipping them for specialized tasks. By feeding them task-specific data and adjusting their internal "knowledge patterns," we refine their responses and hone their abilities. So instead of struggling with medical jargon, a fine-tuned LLM can become a medical information expert, ready to tackle specific questions or tasks you throw its way. It's like customizing a powerful tool for a precise job, making LLMs truly shine in real-world applications.
Fine-Tuning Techniques
Fine-tuning LLMs isn't a one-size-fits-all process. Different techniques offer unique advantages and cater to specific scenarios. Let's explore four key approaches:
Full Model Fine-Tuning: This method treats the LLM like a blank slate, retraining all its layers on the target data. It's powerful for tasks requiring a significant shift in focus, but can be computationally expensive and prone to catastrophic forgetting (losing prior knowledge).
Feature-Based Fine-Tuning: Here, only specific layers or components of the LLM are retrained, leveraging the pre-trained knowledge for general language understanding while adapting to the specific task. This is computationally efficient and minimizes knowledge loss, making it ideal for tasks within the LLM's general domain.
Parameter-Efficient Fine-Tuning: Techniques like LoRA (Low-Rank Adapters) use fewer parameters for fine-tuning, significantly reducing computing resources and training time. This is especially valuable for deploying LLMs on resource-constrained devices, or for rapid experimentation with different tasks.
RLHF Fine-Tuning: Instead of directly training on labeled data, RLHF relies on human feedback to guide LLM improvement. Humans evaluate the model's outputs, providing rewards for desirable outputs and penalties for undesirable ones. The LLM then uses this feedback to adjust its internal parameters, iteratively refining its behavior toward meeting human expectations. This can be particularly helpful for tasks where labeling data is scarce or subjective, and for aligning LLM performance with nuanced human preferences.
Beyond these, there are many other techniques but we will stick to the important ones mentioned above. Choosing the right technique depends on factors like task complexity, available resources, and desired level of adaptation.
Fine-Tuning Tutorial
We need SingleStore Notebooks and Gradient to perform fine-tuning of an LLM on our own custom data.
Activate a free SingleStore trial to access Notebooks.
SingleStore Notebooks are web-based Jupyter notebooks that allow developers to create, explore, visualize, and collaborate on data analysis and workflows using SQL or Python code.
Next, create a free account on Gradient. Gradient is designed to make fine-tuning and inference for open-source LLMs easy.

Make sure to copy and keep the workspace ID and Access tokens safely. We will need them later in our Notebooks.
Go to your Workspace and click on "Fine-Tuning:"
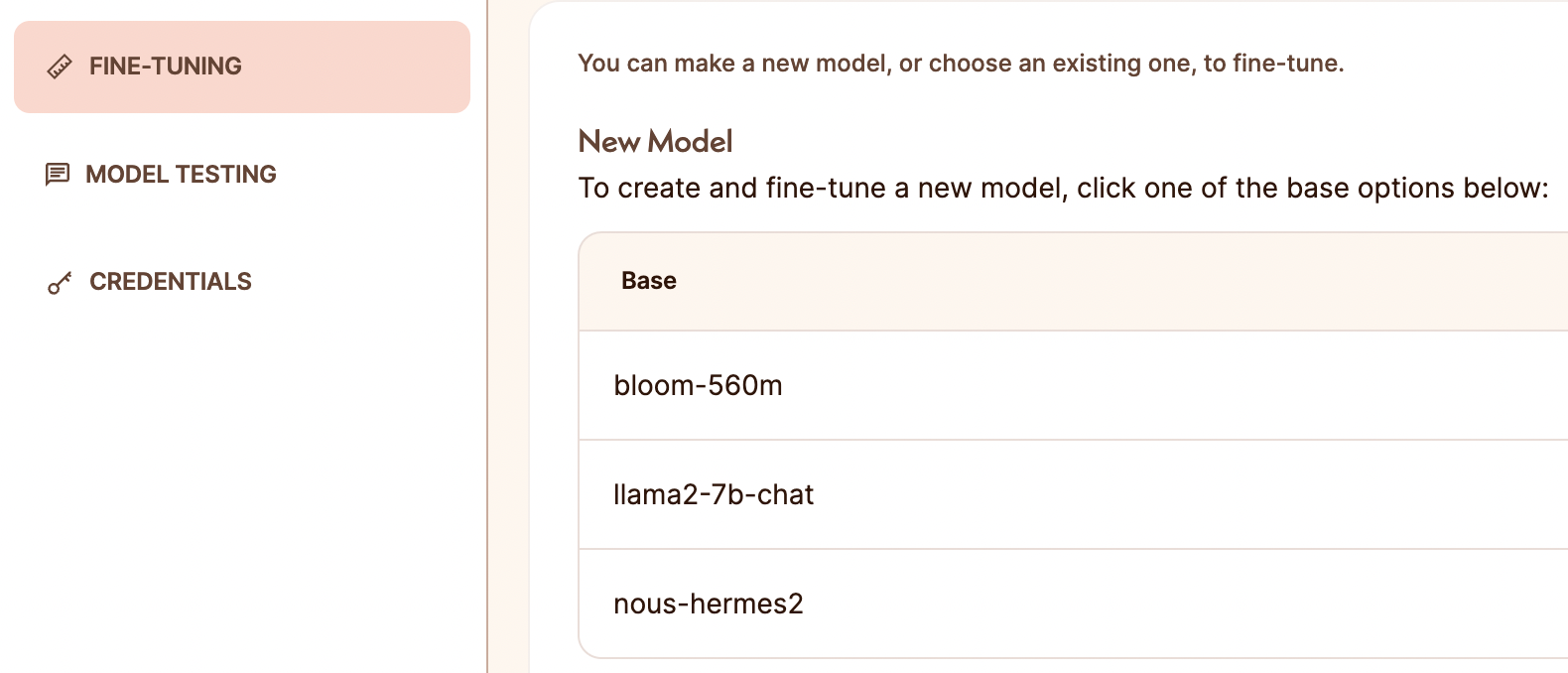
We will fine-tune the base model 'nous-hermes2' mentioned here.
Now, head back to SingleStore Notebooks and create a new Notebook — you can name it whatever you’d like.
Start with installing Gradient AI.
!pip install gradientai --upgradeNext, add the Gradient workspace ID and access key:
import os
os.environ['GRADIENT_WORKSPACE_ID']=''
os.environ['GRADIENT_ACCESS_TOKEN']=''Let's fine-tune the base model (nous-hermes2).
The following script demonstrates the process of fine-tuning the base model ‘nous-hermes2’ on specific data to improve its performance on related tasks or queries.


A new model adapter is created from the base model with the name "Pavanmodel."
The script defines a sample query asking "Who is Pavan Belagatti?" and runs this query through the newly created model adapter before any fine-tuning. It prints the generated response, showcasing the model's performance pre-tuning.
An array of training samples is defined next. Each sample contains an "inputs" field with a specific prompt about Pavan Belagatti and a corresponding response. These samples will be used for fine-tuning the model to better understand and generate information related to these queries.
The script sets the number of epochs for fine-tuning to 3.
In the context of training a machine learning or deep learning model, an epoch is a term used to describe one complete pass through the entire training dataset.
After fine-tuning, the script runs the same initial sample query through the model adapter again. It prints the new generated response to demonstrate the effects of fine-tuning.

The generated output after fine-tuning is just mind-blowing. When asked for the first time, it returned a hallucinated answer saying ‘Pavan Belagatti is an Indian professional badminton player,’ but after the training and fine-tuning with our input data, it gave a proper response.
Make sure to run the step-by-step code inside the SingleStore Notebook that we created at the beginning.
The complete Notebook code is available in my GitHib repository.
As generative AI continues to scale new heights, LLMs are increasingly pivotal in the technological landscape. Organizations are pouring significant investments into generative AI applications, driven by the capabilities of LLMs, to gain a competitive edge and innovate across various sectors. However, the adoption of these sophisticated models to specific data and needs presents considerable challenges.
As highlighted in our comprehensive tutorial, fine-tuning emerges as an indispensable strategy, ensuring these models remain contextually relevant and operationally efficient. This process not only enhances the performance of the LLMs but also tailors them to more effectively meet the unique requirements and objectives of different applications. As we move forward, the iterative refinement of LLMs through fine-tuning will be crucial in unlocking their full potential, paving the way for more personalized, accurate, and efficient AI solutions.
Published at DZone with permission of Pavan Belagatti, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments