Managing a Single-Writer RDBMS for a High-Scale Service
Single-writer RDBMS setup is not good for high-scale services. The data store should be horizontally scalable.
Join the DZone community and get the full member experience.
Join For FreeThis article describes my experience operating a high-scale service backed by a single-writer RDBMS. The system's design was good for a quick launch and maybe an initial few years while the traffic was less. However, it resulted in a lot of pain once the scale increased, and the database problems caused many customer outages and heavy operational load for the team. I will recount the details, lessons learned, and advice for avoiding similar mistakes.
What Happened?
The service had many hosts servicing the typical CRUD (Create, Read, Update, and Delete) APIs backed by MySQL running on three very beefy hosts. One host acted as leader, servicing writes and strongly consistent reads (i.e., reading the most updated value), and two followers continuously syncing updates from the leader working as real-only:
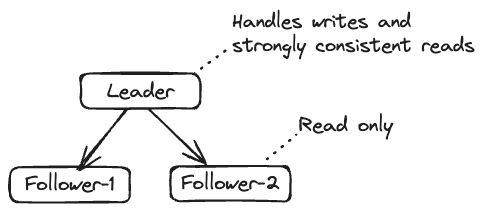
The service had about 100k write requests per second at the peak time with about 5x read traffic. Since all of the write traffic, all of the strongly consistent read traffic, and about 1/3rd of the average read traffic will go to the leader, it resulted in the highest amount of traffic going to the leader at the peak time and overload it: 
Impact of the Leader Host Overload
Since the leader is overloaded at the peak traffic time, about 2-3 times every week, the leader host would become unresponsive, resulting in 100% write and 40% read failures. It triggers the alarm to page the on-call, who would manually execute the failover script to make one of the followers a leader.
Apart from a complete outage, multiple times daily slowdowns of the leader database would trigger an alarm for the on-call. These were more annoying since there wasn't any simpler mitigation than waiting for the load spike to subside.
These regularly repeating operational incidents made the on-call very stressful, resulting in high attrition. The service was top-rated among internal and external customers who were critically dependent on it, and these incidents hampered the customer experience significantly, resulting in a backlash, writing incident reports, and pressure from the management for a permanent fix.
The Remedy
The single-writer database model is a formidable bottleneck for the system's scalability. However, it was obvious that building a truly horizontally scalable datastore sufficient for many years wouldn't be quick. So, while we funded a long-term project, for the medium term, I took the responsibility of reducing the load on the leader database to give us a few years of runway.
We had a strong system engineer who squeezed as much performance out of the database as possible by tuning OS and MySQL parameters. They optimized the database, dropped some unused indices, and pruned the deleted records more aggressively. However, the benefits were marginal.
Our initial approach was cautiously increasing the number of follower databases that can be used as the leader. This wasn't trivial as the original three hosts were running many years old hardware type, which wasn't available anymore, and it's risky to directly use a new hardware type without vetting it cautiously. We initially started with testing and tuning a host as read-only, then testing it as a leader off-peak, gradually gaining confidence. Eventually, we built many follower hosts or read replicas to spread the read load and eliminate the weakly consistent read load from the leader host:

Spreading the read load to more replicas could only help to a limited extent. So, we systematically studied all service APIs, resulting in a write or a strongly consistent read (which must go to the leader). Several changes were made to turn the APIs to reduce the load on the leader. Some of these changes included reducing or eliminating the API calls. For example:
- For some internal background operations, we reduced concurrency and increased backoff with jitter to mitigate the peak load on the leader.
Found and eliminated some internal APIs where the use case was irrelevant, but it was still sending traffic to the leader.
For many strongly consistent read cases, we introduced a new semi-strongly consistent read mode, which reads from an updated follower (i.e., a follower is just a few seconds behind). This was acceptable for many internal use cases and reduced traffic to the leader.
For some APIs doing multiple writes, we batched them as a single write.
Finally, we made the replication chain multi-tiered so that only a limited number of followers replicate from the leader and the remaining replicate from those followers, something like a 3-level tree:
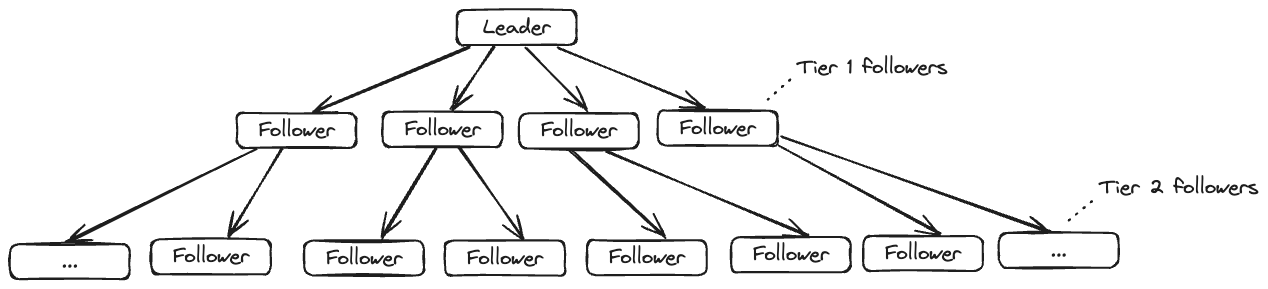
With all of these optimizations, we reduced the peak load on the leader by over 40%, eliminating the overload and reducing the number of pages from 8 per week to less than 1 per month (over 90%). This allowed us to create the new data store and gradually migrate to it while safely running the production services.
Lessons Learned
The primary lesson is it's okay to manage your database for the short run for quickly building and launching the product. However, once the product succeeds, have a plan ready to migrate to a horizontally scalable architecture.
Don't underestimate the effort required to operate a tier-0 service with high availability expectations. Hence, consider the operational cost of running the service as well. Ideally, go for hosted services like AWS Aurora rather than building and operating it on your own.
Have metrics and alarms from the database layer to log latency, fault rate, etc, per service API to give you visibility into what's happening. Revisit your APIs and database interactions periodically to ensure optimal implementation that doesn't put undue stress on the databases.
Anticipate and plan for problems, examine operational procedures to automate various repetitive actions like schema changes (those were extremely painful), failovers (to promote a follower database to a leader), and upgrades. We were stuck with an ancient version of MySQL with limited automation since the upgrade was quite effortful and repeatedly deprioritized to build a new datastore.
NOTE: If you are interested in learning more about the architecture of the new datastore and how we arrived at it, please feel free to leave a comment, and I will consider covering it in a separate post.
Opinions expressed by DZone contributors are their own.
Comments