Real-Time Data Scrubbing Before Storing in a Data Warehouse
Real-time data scrubbing is essential for accuracy and compliance. Memphis functions can reduce your data warehouse costs and maintain data integrity.
Join the DZone community and get the full member experience.
Join For FreeBetween January 2023 and May 2023, companies violating general data processing principles incurred fines totaling 1.86 billion USD (!!!).
In today’s data-driven landscape, the importance of data accuracy and compliance cannot be overstated. As businesses amass vast amounts of information, the need to ensure data integrity, especially PII storing, becomes paramount. Data scrubbing emerges as a crucial process, particularly in real-time scenarios, before storing information in a data warehouse.
Data Scrubbing in the Context of Compliance
Data scrubbing, often referred to as data cleansing or data cleaning, involves the identification and rectification of errors or inconsistencies in a dataset. In the context of compliance, it means removing certain values that qualify as PII that cannot be stored or should be handled differently.
Real-time data scrubbing takes the cleansing process a step further by ensuring that incoming data is cleaned and validated instantly, before being stored in a data warehouse.
Compliance standards, such as GDPR, HIPAA, or industry-specific regulations, mandate stringent requirements for data accuracy, privacy, and security. Failure to adhere to these standards can result in severe repercussions, including financial penalties and reputational damage. Real-time data scrubbing acts as a robust preemptive measure, ensuring that only compliant data is integrated into the warehouse.
Event-Driven Scrubbing
Event-driven applications stand as stateful systems that intake events from one or multiple streams and respond to these incoming events by initiating computations, updating their state, or triggering external actions.
They represent a progressive shift from the conventional application structure that segregates computation and data storage into distinct tiers. In this novel architecture, these applications retrieve data from and save data to a remote transactional database.
In stark contrast, event-driven applications revolve around stateful stream processing frameworks. This approach intertwines data and computation, facilitating localized data access either in-memory or through disk storage. To ensure resilience, these applications implement fault-tolerance measures by periodically storing checkpoints in remote persistent storage.
In the context of Scrubbing, it means that the actual action of scrubbing will take place for each ingested event in real-time, powering up only when new events arrive and immediately after, not based on constant times, usually performed on top of the database, after being stored, meaning the potential violation already took place.
How Does Memphis Functions Support Such a Use Case?
At times, a more comprehensive policy-driven cleansing may be necessary. However, if a quick, large-scale ‘eraser’ is what you require, Memphis Functions can offer an excellent solution. The diagram illustrates two options: data sourced from either a Kafka topic or a Memphis station, potentially both concurrently. This data passes through a Memphis Function named ‘remove-fields‘ before progressing to the data warehouse for further storage.
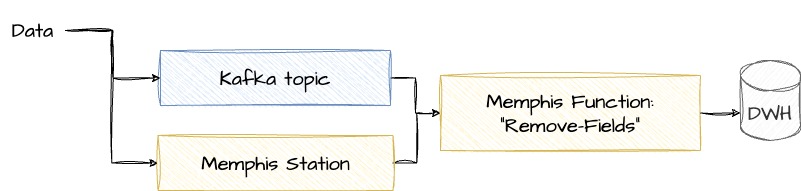
Behind the curtain, events or streaming data are grouped into batches, a configuration determined by the user’s specifications. These batches then undergo processing via a serverless function, specifically the ‘remove-fields’ function, meticulously designed to cleanse the ingested data according to pre-established rules. Following this scrubbing process, the refined data is either consumed internally or routed to a different Kafka topic, alternatively being swiftly directed straight to the Data Warehouse (DWH) for immediate utilization.
Usage Example
Before
{ "id": 123456789, "full_name": "Peter Parker", "gender": "male" }After (Removing ‘gender’)
{ "id": 123456789, "full_name": "Peter Parker", }Next Steps
An ideal follow-up action would involve implementing schema enforcement. Data warehouses are renowned for their rigorous schema enforcement practices. By integrating both a transformation layer and schema validation, it’s possible to significantly elevate data quality while reducing the risk of potential disruptions or breaks in the system. This can simply take place by attaching a Schemaverse schema to the station.
Published at DZone with permission of Idan Asulin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments