Scaling SRE Teams: The Challenges and How To Build a Successful Scaling Framework
Scaling teams of site reliability engineers comes with many challenges. Here, explore the challenges of scaling and review a successful scaling framework.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Observability and Application Performance Trend Report.
For more:
Read the Report
From cultural and structural challenges within an organization to balancing daily work and dividing it between teams and individuals, scaling teams of site reliability engineers (SREs) comes with many challenges. However, fostering a resilient site reliability engineering (SRE) culture can facilitate the gradual and sustainable growth of an SRE team. In this article, we explore the challenges of scaling and review a successful scaling framework. This framework is suitable for guiding emerging teams and startups as they cultivate an evolving SRE culture, as well as for established companies with firmly entrenched SRE cultures.
The Challenges of Scaling SRE Teams
As teams scale, complexity may increase as it can be more difficult to communicate, coordinate, and maintain a team's coherence. Below is a list of challenges to consider as your team and/or organization grows:
- Rapid growth – Rapid growth leads to more complex systems, which can outpace the capacity of your SRE team, leading to bottlenecks and reduced reliability.
- Knowledge-sharing – Maintaining a shared understanding of systems and processes may become difficult, making it challenging to onboard new team members effectively.
- Tooling and automation – Scaling without appropriate tooling and automation can lead to increased manual toil, reducing the efficiency of the SRE team.
- Incident response – Coordinating incident responses can become more challenging, and miscommunications or delays can occur.
- Maintaining a culture of innovation and learning – This can be challenging as SREs may become more focused on solving critical daily problems and less focused on new initiatives.
- Balancing operational and engineering work – Since SREs are responsible for both operational tasks and engineering work, it is important to ensure that these teams have enough time to focus on both areas.
A Framework for Scaling SRE Teams
Scaling may come naturally if you do the right things in the right order. First, you must identify what your current state is in terms of infrastructure. How well do you understand the systems? Determine existing SRE processes that need improvement. For the SRE processes that are necessary but are not employed yet, find the tools and the metrics necessary to start. Collaborate with the appropriate stakeholders, use feedback, iterate, and improve.
Step 1: Assess Your Current State
Understand your system and create a detailed map of your infrastructure, services, and dependencies. Identify all the components in your infrastructure, including servers, databases, load balancers, networking equipment, and any cloud services you utilize. It is important to understand how these components are interconnected and dependent on each other — this includes understanding which services rely on others and the flow of data between them.
It's also vital to identify and evaluate existing SRE practices and assess their effectiveness:
- Analyze historical incident data to identify recurring issues and their resolutions.
- Gather feedback from your SRE team and other relevant stakeholders.
- Ask them about pain points, challenges, and areas where improvements are needed.
- Assess the performance metrics related to system reliability and availability.
- Identify any trends or patterns that indicate areas requiring attention.
- Evaluate how incidents are currently being handled.
- Are they being resolved efficiently?
- Are post-incident reviews being conducted effectively to prevent recurrences?
Step 2: Define SLOs and Error Budgets
Collaborate with stakeholders to establish clear and meaningful service-level objectives (SLOs) by determining the acceptable error rate and creating error budgets based on the SLOs. SLOs and error budgets can guide resource allocation optimization. Computing resources can be allocated to areas that directly impact the achievement of the SLOs.
SLOs set clear, achievable goals for the team and provide a measurable way to assess the reliability of a service. By defining specific targets for uptime, latency, or error rates, SRE teams can objectively evaluate whether the system is meeting the desired standards of performance. Using specific targets, a team can prioritize their efforts and focus on areas that need improvement, thus fostering a culture of accountability and continuous improvement.
Error budgets provide a mechanism for managing risk and making trade-offs between reliability and innovation. They allow SRE teams to determine an acceptable threshold for service disruptions or errors, enabling them to balance the need for deploying new features or making changes to maintain a reliable service.
Step 3: Build and Train Your SRE Team
Identify talent according to the needs of each and every step of this framework. Look for the right skillset and cultural fit, and be sure to provide comprehensive onboarding and training programs for new SREs. Beware of the golden rule that culture eats strategy for breakfast: Having the right strategy and processes is important, but without the right culture, no strategy or process will succeed in the long run.
Step 4: Establish SRE Processes, Automate, Iterate, and Improve
Implement incident management procedures, including incident command and post-incident reviews. Define a process for safe and efficient changes to the system.

Figure 1: Basic SRE process
One of the cornerstones of SRE involves how to identify and handle incidents through monitoring, alerting, remediation, and incident management. Swift incident identification and management are vital in minimizing downtime, which can prevent minor issues from escalating into major problems.
By analyzing incidents and their root causes, SREs can identify patterns and make necessary improvements to prevent similar issues from occurring in the future. This continuous improvement process is crucial for enhancing the overall reliability and performance whilst ensuring the efficiency of systems at scale. Improving and scaling your team can go hand in hand.
Monitoring
Monitoring is the first step in ensuring the reliability and performance of a system. It involves the continuous collection of data about the system's behavior, performance, and health.
This can be broken down into:
- Data collection – Monitoring systems collect various types of data, including metrics, logs, and traces, as shown in Figure 2.
- Real-time observability – Monitoring provides real-time visibility into the system's status, enabling teams to identify potential issues as they occur.
- Proactive vs. reactive – Effective monitoring allows for proactive problem detection and resolution, reducing the need for reactive firefighting.
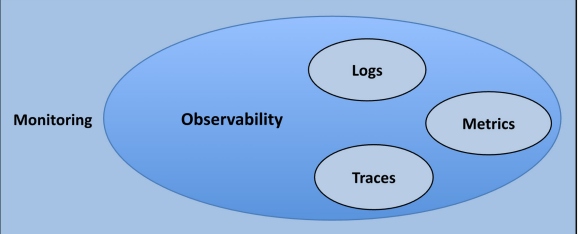
Figure 2: Monitoring and observability
Alerting
This is the process of notifying relevant parties when predefined conditions or thresholds are met. It's a critical prerequisite for incident management. This can be broken down into:
- Thresholds and conditions – Alerts are triggered based on predefined thresholds or conditions. For example, an alert might be set to trigger when CPU usage exceeds 90% for five consecutive minutes.
- Notification channels – Alerts can be sent via various notification channels, including email, SMS, or pager, or even integrated into incident management tools.
- Severity levels – Alerts should be categorized by severity levels (e.g., critical, warning, informational) to indicate the urgency and impact of the issue.
Remediation
This involves taking actions to address issues detected through monitoring and alerting. The goal is to mitigate or resolve problems quickly to minimize the impact on users.
- Automated actions – SRE teams often implement automated remediation actions for known issues. For example, an automated scaling system might add more resources to a server when CPU usage is high.
- Playbooks – SREs follow predefined playbooks that outline steps to troubleshoot and resolve common issues. Playbooks ensure consistency and efficiency during remediation efforts.
- Manual interventions – In some cases, manual intervention by SREs or other team members may be necessary for complex or unexpected issues.
Incident Management
Effective communication, knowledge-sharing, and training are crucial during an incident, and most incidents can be reproduced in staging environments for training purposes. Regular updates are provided to stakeholders, including users, management, and other relevant teams.
Incident management includes a culture of learning and continuous improvement: The goal is not only to resolve the incident but also to prevent it from happening again.
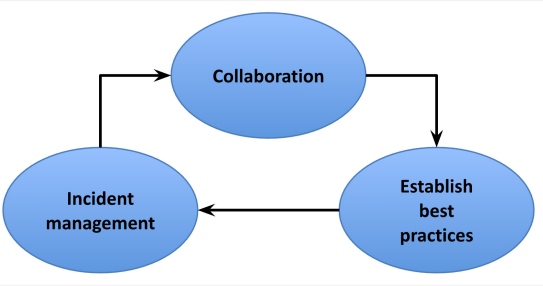
Figure 3: Handling incidents
A robust incident management process ensures that service disruptions are addressed promptly, thus enhancing user trust and satisfaction. In addition, by effectively managing incidents, SREs help preserve the continuity of business operations and minimize potential revenue losses.
Incident management plays a vital role in the scaling process since it establishes best practices and promotes collaboration, as shown in Figure 3. As the system scales, the frequency and complexity of incidents are likely to increase. A well-defined incident management process enables the SRE team to manage the growing workload efficiently.
Conclusion
SRE is an integral part of the SDLC. At the end of the day, your SRE processes should be integrated into the entire process of development, testing, and deployment, as shown in Figure 4.
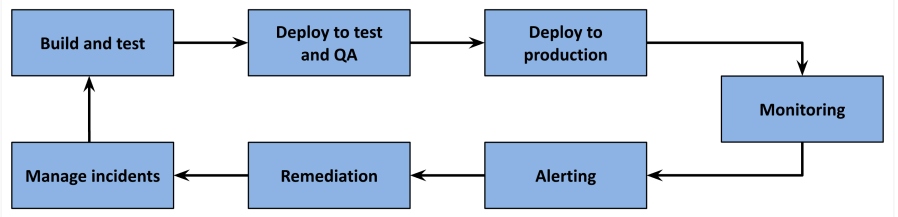
Figure 4: Holistic view of development, testing, and the SRE process
Iterating on and improving the steps above will inevitably lead to more work for SRE teams; however, this work can pave the way for sustainable and successful scaling of SRE teams at the right pace.
By following this framework and overcoming the challenges, you can effectively scale your SRE team while maintaining system reliability and fostering a culture of collaboration and innovation. Remember that SRE is an ongoing journey, and it is essential to stay committed to the principles and practices that drive reliability and performance.
This is an article from DZone's 2023 Observability and Application Performance Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments