Serverless Extraction and Processing of CSV Content From a Zip File With Zero Coding
This article demonstrates the implementation of a serverless function in AWS using Kumologica for unzipping and extracting CSV file content.
Join the DZone community and get the full member experience.
Join For FreeIn the field of IT, file extraction and processing refer to the process of extracting information from various types of files, such as text files, images, videos, and audio files, and then processing that information to make it usable for a specific purpose.
File extraction involves reading and parsing the data stored in a file, which could be in a variety of formats, such as PDF, CSV, XML, or JSON, among others. Once the information is extracted, it can be processed using various techniques such as data cleansing, transformation, and analysis to generate useful insights.
File processing is a crucial part of many IT applications, including data warehousing, business intelligence, and data analytics. For example, in the context of data warehousing, file extraction, and processing are used to extract data from various sources and transform it into a format that is suitable for analysis and reporting. Similarly, in the context of business intelligence, file processing can be used to generate reports and dashboards that provide insights into key business metrics.
In this article, we will see how file extraction and processing are carried out in a serverless world. For this, we will go through a use case, design a solution on serverless infrastructure such as AWS Lambda and Amazon S3, and implement it using Kumologica Designer.
Use Case
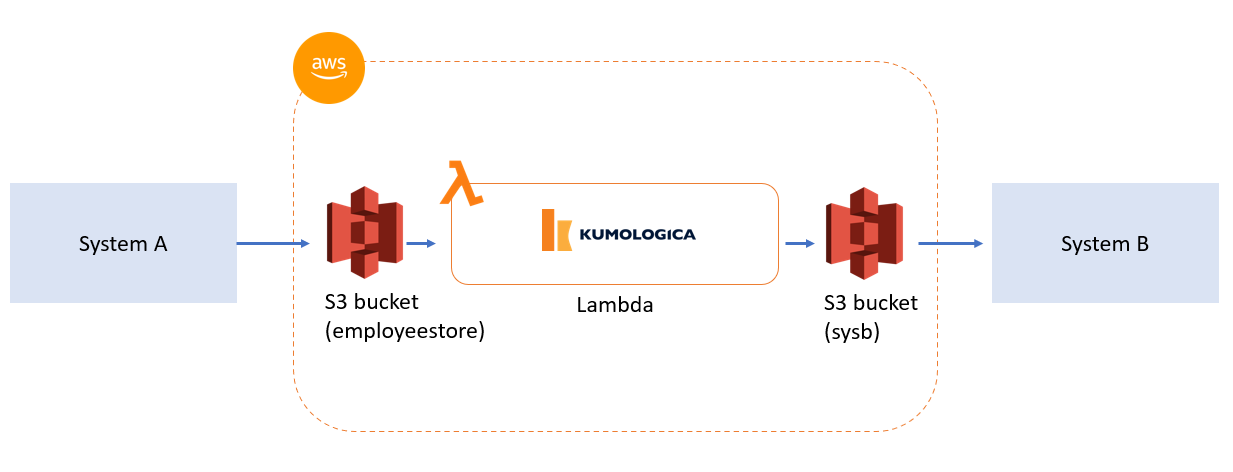
ABC Corp is an enterprise that gets employee details from an onboarding system A as a zip file containing a CSV file. The CSV file has the employee name, dob, role, employee id, employee status, location, and phone number. Employee name, location, and employment status are required by system B for access provisioning. An integration service needs to be developed that need to sync the data from system A to system B.
![Integration Interface]() Solution
Solution
 Solution
SolutionThe enterprise is having AWS as its cloud provider, so we are going to build this integration solution using AWS serverless services such as AWS Lambda and Amazon S3 bucket. In this solution system, A is going to drop a zip file containing the CSV file with the employee information to an Amazon S3 bucket (employeestore). Whenever a new zip file is detected, the integration service needs to pull the zip file from the specific S3 bucket. The zip file received from the S3 bucket is unzipped by the integration service, and the CSV file is parsed to retrieve the necessary content. The content is then transformed as JSON content, and the JSON file is placed in sysb Amazon S3 bucket. System B will then read the data from the sysb bucket.
![Kumologica]() Pre-Requisites
Pre-Requisites
 Pre-Requisites
Pre-Requisites- Having an AWS cloud account with necessary IAM access or user having permissions (As prescribed during Kumologica designer installation).
- AWS profile configured in your machine.
- Create two AWS S3 bucket with the name — employeestore and sysb, respectively.
- Install Kumologica Designer.
- The zip file has the CSV content as given below:
employee_name, dob, role, employee_id, employee_status, location, phone_number
Tom,08/04/87,developer,123,active,220 George st Sydney,613459034
Harry,01/05/89,manager,345,active,220 George st Sydney,613959034
Jina,02/05/94,developer,442,inactive,10 Carmen st Melbourne,613779034
Jack,07/01/85,Analyst,190,active,,220 George st Sydney,613453333Implementation
Let's get started implementing the solution by first opening the Kumologica Designer by using the command kl open via terminal or Windows command line.
1. Create a new project by providing the Project name and employeesync service.
2. Install the ZIP node in the workspace by opening a command line or terminal and going to the path of your project workspace (location of the project package.json). Enter the following npm command to install.
npm i @kumologica/kumologica-contrib-zip3. Restart the designer.
4. Drag and drop the EvenListener node from the palette to the canvas and select AmazonS3 from the drop-down. This is for flow to accept Amazon S3 trigger events when a file is created in the S3 bucket.
5. Add a logger and wire it to the EventListener node. Provide the following configuration.
Display Name : Log_entry
Level: INFO
Message : msg.payload
Log format : String6. Add an S3 node and wire to the logger. Provide the following configuration.
Display Name : GetEmployeeFile
Operation : GetObject
Bucket : employeestore
Key : employeeinfo.zip
RequestTimeout : 100007. Drop the ZIP node to canvas and wire it to the S3 node. Provide the following configuration.
Operation : Extract
Content : msg.payload.Body8. Add a Function node and wire to the ZIP node. Provide the following code.
msg.payload = msg.payload[0].content.toString()9. Drop a CSV node for parsing. Wire the CSV node to the Function node.
Display Name : CSV
Columns : employee_name, dob, role, employee_id, employee_status, location, phone_number
Seperator : Comma
10. Add the S3 bucket node for pushing the JSON content to the sysb bucket.
Display Name : PushtoSysBBucket
Operation : PutObject
Bucket : sysb
Key : employeeinfo.json
Content : msg.payload
11. Finally, we will end the flow by adding the EventListenerEnd node.
Payload : {"status" : "completed"}Now it's time to deploy the service.
Deployment
- Select the CLOUD tab on the right panel of Kumologica Designer, and select your AWS Profile.
- Go to the “Trigger” section under the Cloud tab and select the S3 bucket (employeestore) where the CSV file is expected.
- Click the Deploy button.
Conclusion
The Kumologica designer simplifies the deployment process by automatically packaging the flow as a lambda zip file and generating an AWS cloud formation script. This script deploys the flow as a node.js-based AWS function and creates a trigger for an S3 bucket. With this serverless service, minimal coding is required. We hope you found this article informative and look forward to sharing our next tutorial with you.
Opinions expressed by DZone contributors are their own.
Comments