The Convergence of Testing and Observability
While the popularity of observability is a somewhat recent development, it is exciting to see what benefits it can bring to testing. Find out more in this post.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Automated Testing Trend Report.
For more:
Read the Report
One of the core capabilities that has seen increased interest in the DevOps community is observability. Observability improves monitoring in several vital ways, making it easier and faster to understand business flows and allowing for enhanced issue resolution. Furthermore, observability goes beyond an operations capability and can be used for testing and quality assurance.
Testing has traditionally faced the challenge of identifying the appropriate testing scope. "How much testing is enough?" and "What should we test?" are questions each testing executive asks, and the answers have been elusive. There are fewer arguments about testing new functionality; while not trivial, you know the functionality you built in new features and hence can derive the proper testing scope from your understanding of the functional scope. But what else should you test? What is a comprehensive general regression testing suite, and what previous functionality will be impacted by the new functionality you have developed and will release?
Observability can help us with this as well as the unavoidable defect investigation. But before we get to this, let's take a closer look at observability.
What Is Observability?
Observability is not monitoring with a different name. Monitoring is usually limited to observing a specific aspect of a resource, like disk space or memory of a compute instance. Monitoring one specific characteristic can be helpful in an operations context, but it usually only detects a subset of what is concerning. All monitoring can show is that the system looks okay, but users can still be experiencing significant outages.
Observability aims to make us see the state of the system by making data flows "observable." This means that we can identify when something starts to behave out of order and requires our attention. Observability combines logs, metrics, and traces from infrastructure and applications to gain insights. Ideally, it organizes these around workflows instead of system resources and, as such, creates a functional view of the system in use. Done correctly, it lets you see what functionality is being executed and how frequently, and it enables you to identify performance characteristics of the system and workflow.
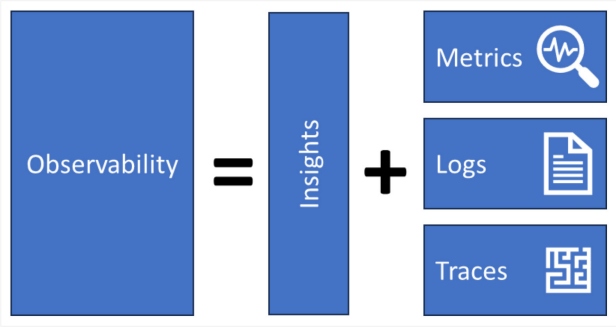
Figure 1: Observability combines metrics, logs, and traces for insights
One benefit of observability is that it shows you the actual system. It is not biased by what the designers, architects, and engineers think should happen in production. It shows the unbiased flow of data. The users, over time (and sometimes from the very first day), find ways to use the system quite differently from what was designed. Observability makes such changes in behavior visible. Observability is incredibly powerful in debugging system issues as it allows us to navigate the system to see where problems occur.
Observability requires a dedicated setup and some contextual knowledge similar to traceability. Traceability is the ability to follow a system transaction over time through all the different components of our application and infrastructure architecture, which means you have to have common information like an ID that enables this. OpenTelemetry is an open standard that can be used and provides useful guidance on how to set this up. Observability makes identifying production issues a lot easier. And we can use observability for our benefit in testing, too.
Observability of Testing: How to Look Left
Two aspects of observability make it useful in the testing context: Its ability to make the actual system usage observable and its usefulness in finding problem areas during debugging. Understanding the actual system behavior is most directly useful during performance testing. Performance testing is the pinnacle of testing since it tries to achieve as close to the realistic peak behavior of a system as possible. Unfortunately, performance testing scenarios are often based on human knowledge of the system instead of objective information.
For example, performance testing might be based on the prediction of 10,000 customer interactions per hour during a sales campaign based on the information of the sales manager. Observability information can help define the testing scenarios by using the information to look for the times the system was under the most stress in production and then simulate similar situations in the performance test environment.
We can use a system signature to compare behaviors. A system signature in the context of observability is the set of values for logs, metrics, and traces during a specific period. Take, for example, a marketing promotion for new customers. The signature of the system should change during that period to show more new account creations with its associated functionality and the related infrastructure showing up as being more "busy."
If the signature does not change during the promotion, we would predict that we also don't see the business metrics move (e.g., user sign-ups). In this example, the business metrics and the signature can be easily matched.
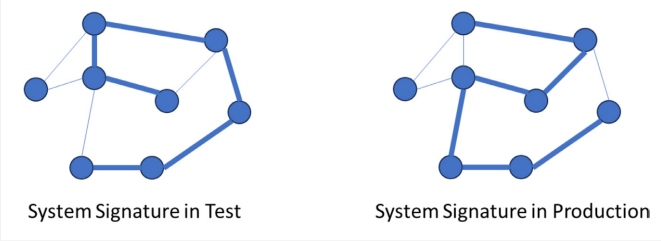
Figure 2: A system behaving differently in test, which shows up in the system signature
In many other cases, this is not true. Imagine an example where we change the recommendation engine to use our warehouse data going forward. We expect the system signature to show increased data flows between the recommendation engine and our warehouse system. You can see how system signatures and the changes of the system signature can be useful for testing; any differences in signature between production and the testing systems should be explainable by the intended changes of the upcoming release. Otherwise, investigation is required.
In the same way, information from the production observability system can be used to define a regression suite that reflects the functionality most frequently used in production. Observability can give you information about the workflows still actively in use and which workflows have stopped being relevant. This information can optimize your regression suite both from a maintenance perspective and, more importantly, from a risk perspective, making sure that core functionality, as experienced by the user, remains in a working state.
Implementing observability in your test environments means you can use the power of observability for both production issues and your testing defects. It removes the need for debugging modes to some degree and relies upon the same system capability as production. This way, observability becomes how you work across both dev and ops, which helps break down silos.
Observability for Test Insights: Looking Right
In the previous section, we looked at using observability by looking left or backward, ensuring we have kept everything intact. Similarly, we can use observability to help us predict the success of the features we deliver. Think about a new feature you are developing. During the test cycles, we see how this new feature changes the workflows, which shows up in our observability solution. We can see the new features being used and other features changing in usage as a result.
The signature of our application has changed when we consider the logs, traces, and metrics of our system in test. Once we go live, we predict that the signature of the production system will change in a very similar way. If that happens, we will be happy. But what if the signature of the production system does not change as predicted?
Let's take an example: We created a new feature that leverages information from previous bookings to better serve our customers by allocating similar seats and menu options. During testing, we tested the new feature with our test data set, and we see an increase in accessing the bookings database while the customer booking is being collated. Once we go live, we realize that the workflows are not utilizing the customer booking database, and we leverage the information from our observability tooling to investigate.
We have found a case where the users are not using our new features or are not using the features in the expected way. In either case, this information allows us to investigate further to see whether more change management is required for the users or whether our feature is just not solving the problem in the way we wanted it to. Another way to use observability is to evaluate the performance of your changes in test and the impact on the system signature — comparing this afterwards with the production system signature can give valuable insights and prevent overall performance degradation.
Our testing efforts (and the associated predictions) have now become a valuable tool for the business to evaluate the success of a feature, which elevates testing to become a business tool and a real value investment.
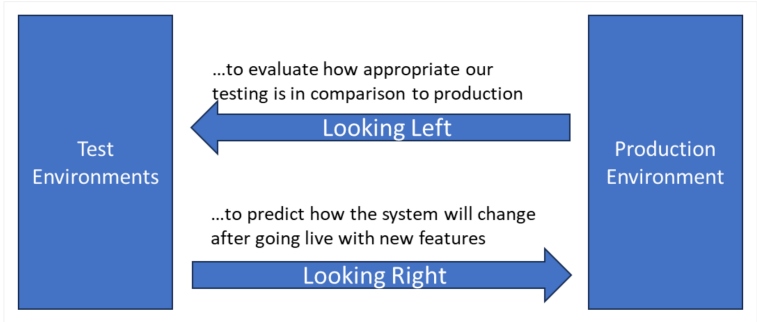
Figure 3: Using observability in test by looking left and looking right
Conclusion
While the popularity of observability is a somewhat recent development, it is exciting to see what benefits it can bring to testing. It will create objectiveness for defining testing efforts and results by evaluating them against the actual system behavior in production. It also provides value to developer, tester, and business communities, which makes it a valuable tool for breaking down barriers. Using the same practices and tools across communities drives a common culture — after all, culture is nothing but repeated behaviors.
This is an article from DZone's 2023 Automated Testing Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments