The Normalization Spectrum
Let's take a look at the data normalization spectrum.
Join the DZone community and get the full member experience.
Join For Free
Most databases (old and new) recommend, and in some cases force, an application to model its data in either a fully normalized or fully denormalized model. However, as we will see, matching the complexity of enterprise applications with modern-day data requirements cannot be achieved by only either end of that spectrum.
You may also like: Pros and Cons of Database Normalization
Normalized Data Model
Normalization is defined as the process of reducing or eliminating redundancy across a dataset.
It has become the defacto approach to modeling data in a relational database, largely due to the underlying resource limitations that these systems were originally designed around: slow disk and expensive RAM. Less data redundancy/duplication means more efficient reading from disk and less space taken up. Even some NoSQL databases like Cassandra encourage a very normalized approach to storing data.
Normalization typically entails creating a series of tables, each of which can have a different set of fields, but where each record in a given table must have a value for all of its fields — no more, no less. Any application with a reasonably sophisticated data model ends up splitting that data across 10s if not 100s or even 1000s of tables. Across these tables, data is linked together with “relationships” (i.e. a record stored in table1 contains a link to a record in table2). These tables, fields, and relationships are what is known as a “schema.”
Normalizing data does provide some benefit:
- Data Deduplication: storing a given value once and referencing it from multiple locations saves storage space.
- Consistency: Similarly, updating a value that is only stored in one location and referenced from others means that updates can be applied once and there are no inconsistencies.
- Data Integrity: Normalization is often associated with the ability of a database to only accept incoming data that matches the right fields (and sometimes even the datatype of those fields). However, I would argue that while this is a beneficial capability, it does not stem directly from a normalized data model and rather from the underlying implementation.
However, it also has a number of drawbacks:
- As data comes into the system, it must be divided up across these numerous tables, and it can be quite resource-intensive to ensure everything stays updated together (i.e. transactions and relational integrity).
- Complex (i.e. slow) JOINs are then required to piece together values from many tables when an application requests multiple data points.
- All records within a table must be identical, making it very challenging (nearly impossible) to store data of varying structure. Introducing data of a different format from the current model requires new tables, and changing from one structure to another can require significant downtime.
- Impedance mismatch: The way modern applications deal with their data (i.e. objects) is very different than the way it gets stored in or retrieved from the database.
Denormalized Data Model
On the other end of the spectrum, we have denormalization, a strategy typically used to increase performance by grouping like data together. Data was historically denormalized to improve reporting performance in a Data Warehouse by avoiding the need for complex JOINs across tables. This introduces the added challenge of keeping data up-to-date across more than one model but we will save a discussion on brittle ETL pipelines for another day.
In some modern (i.e. NoSQL) databases, denormalization has been touted as the cure-all to the challenges of relational databases. Developers are told to denormalize EVERYTHING so that they can get the flexibility and performance that modern web and mobile applications require. For simple data models, this is easy to do and does provide significant benefits. However, for more complex data models, it can actually make development harder.
The benefits of denormalization are:
- Reduced impedance mismatch (for simple applications)
- Easy variation of schema from one record to another
- Improved performance by inserting all related data in one shot, and removing JOINs across tables for retrieval.
However, it too has tradeoffs:
- Data Duplication: The same values are duplicated multiple times throughout the database, increase storage and processing requirements.
- Data Inconsistency: Duplication of data means making an update to one value requires changing that value in multiple places. Since this usually can’t be done all at once (or at least not at scale) the result is inconsistency while that update is being made
- Hard to model complex relationships, actually increasing impedance mismatch for enterprise applications. Multiple components of a complex application will all need to operate on the same data at different times in different ways. Forcing them all to cooperate (or compete) in a single record is practically impossible.
Ironically, just in the same way that a normalized data model is developed due to the limitations of RAM and disk, the recommendation for denormalization developed from the deficiencies of some early NoSQL technologies: no support for efficient JOINs across tables and lack of strong consistency (even on a single record) to allow references between records.
Hybrid Normalized/Denormalized Data Models
One very powerful aspect of Couchbase is its support a wide range of hybrid normalized and denormalized data models. Denormalization is easily achieved with JSON and normalization with support for JOIN coupled with strong consistency...and both can sit side-by-side.
Let’s take an example of customers, their orders and the products that they’ve purchased:

- The fully normalized data model yields good deduplication of data across multiple orders. However, it would be quite challenging to add a second (or third, fourth, etc) address field for each customer after the system is live. Or perhaps to add reviews to only some products and not others.
- On the other hand, the fully denormalized data model makes it very easy to have one customer with 1 address and another customer with 2. However, updating the description of a product across all orders could be quite intensive (i.e. slow) and result in two different descriptions for the same product depending on when the database was queried. It also results in heavy duplication of customer details as well as product names and descriptions which results in more resources to store, process, backup, etc.
Wouldn’t it be great if you could get the best of both worlds and only make the tradeoffs that suit a particular requirement?
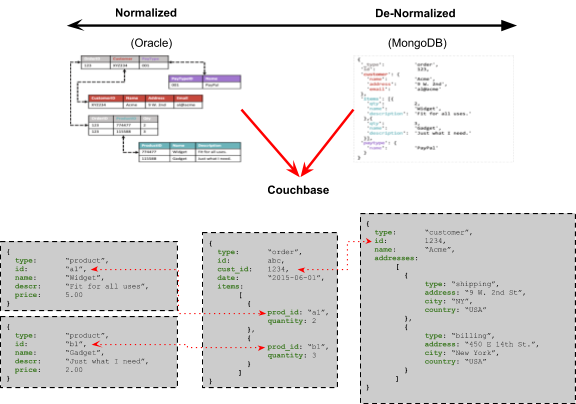
As you can see from the above diagram, with Couchbase it’s possible to have both a normalized AND a denormalized data model in the same schema. This data is normalized where it makes sense: using references from order to products and customers to avoid any data duplication or inconsistency. It is also denormalized where it makes sense: keeping all of the customer data together in a single record and allowing different customers to have different information. It’s even a mix of both in the same record: while orders refer to products and customers, they also contain an arbitrary list of items contained within that order. It just makes sense.
This is only possible when using a database that can not only support strong consistency but can also have a powerful query language for expressing the complex relationships between data records.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments