Implementing RAG With Spring AI and Ollama Using Local AI/LLM Models
In this article, learn how to use AI with RAG independent from external AI/LLM services with Ollama-based AI/LLM models.
Join the DZone community and get the full member experience.
Join For FreeThis article is based on this article that describes the AIDocumentLibraryChat project with a RAG-based search service based on the Open AI Embedding/GPT model services.
The AIDocumentLibraryChat project has been extended to have the option to use local AI models with the help of Ollama. That has the advantage that the documents never leave the local servers. That is a solution in case it is prohibited to transfer the documents to an external service.
Architecture
With Ollama, the AI model can run on a local server. That changes the architecture to look like this:
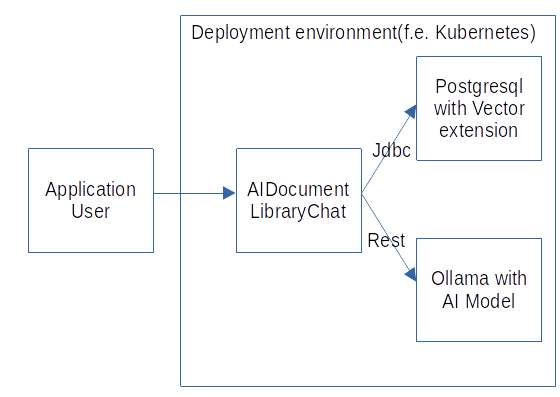
The architecture can deploy all needed systems in a local deployment environment that can be controlled by the local organization. An example would be to deploy the AIDocumentLibraryChat application, the PostgreSQL DB, and the Ollama-based AI Model in a local Kubernetes cluster and to provide user access to the AIDocumentLibraryChat with an ingress. With this architecture, only the results are provided by the AIDocumentLibraryChat application and can be accessed by external parties.
The system architecture has the UI for the user and the application logic in the AIDocumentLibraryChat application. The application uses Spring AI with the ONNX library functions to create the embeddings of the documents. The embeddings and documents are stored with JDBC in the PostgreSQL database with the vector extension. To create the answers based on the documents/paragraphs content, the Ollama-based model is called with REST. The AIDocumentLibraryChat application, the Postgresql DB, and the Ollama-based model can be packaged in a Docker image and deployed in a Kubernetes cluster. That makes the system independent of external systems. The Ollama models support the needed GPU acceleration on the server.
The shell commands to use the Ollama Docker image are in the runOllama.sh file. The shell commands to use the Postgresql DB Docker image with vector extensions are in the runPostgresql.sh file.
Building the Application for Ollama
The Gradle build of the application has been updated to switch off OpenAI support and switch on Ollama support with the useOllama property:
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.1'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'ch.xxx'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '21'
}
repositories {
mavenCentral()
maven { url "https://repo.spring.io/snapshot" }
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.ai:spring-ai-tika-document-reader:
0.8.0-SNAPSHOT'
implementation 'org.liquibase:liquibase-core'
implementation 'net.javacrumbs.shedlock:shedlock-spring:5.2.0'
implementation 'net.javacrumbs.shedlock:
shedlock-provider-jdbc-template:5.2.0'
implementation 'org.springframework.ai:
spring-ai-pgvector-store-spring-boot-starter:0.8.0-SNAPSHOT'
implementation 'org.springframework.ai:
spring-ai-transformers-spring-boot-starter:0.8.0-SNAPSHOT'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.security:spring-security-test'
testImplementation 'com.tngtech.archunit:archunit-junit5:1.1.0'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
if(project.hasProperty('useOllama')) {
implementation 'org.springframework.ai:
spring-ai-ollama-spring-boot-starter:0.8.0-SNAPSHOT'
} else {
implementation 'org.springframework.ai:
spring-ai-openai-spring-boot-starter:0.8.0-SNAPSHOT'
}
}
bootJar {
archiveFileName = 'aidocumentlibrarychat.jar'
}
tasks.named('test') {
useJUnitPlatform()
}The Gradle build adds the Ollama Spring Starter and the Embedding library with 'if(project.hasProperty('useOllama))' statement, and otherwise, it adds the OpenAI Spring Starter.
Database Setup
The application needs to be started with the Spring Profile 'ollama' to switch on the features needed for Ollama support. The database setup needs a different embedding vector type that is changed with the application-ollama.properties file:
...
spring.liquibase.change-log=classpath:/dbchangelog/db.changelog-master-ollama.xml
...The spring.liquibase.change-log property sets the Liquibase script that includes the Ollama initialization. That script includes the db.changelog-1-ollama.xml script with the initialization:
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="8" author="angular2guy">
<modifyDataType tableName="vector_store" columnName="embedding"
newDataType="vector(384)"/>
</changeSet>
</databaseChangeLog>The script changes the column type of the embedding column to vector(384) to support the format that is created by the Spring AI ONNX Embedding library.
Add Ollama Support to the Application
To support Ollama-based models, the application-ollama.properties file has been added:
spring.ai.ollama.base-url=${OLLAMA-BASE-URL:http://localhost:11434}
spring.ai.ollama.model=stable-beluga:13b
spring.liquibase.change-log=classpath:/dbchangelog/db.changelog-master-ollama.xml
document-token-limit=150The spring.ai.ollama.base-url property sets the URL to access the Ollama model. The spring.ai.ollama.model sets the name of the model that is run in Ollama. The document-token-limit sets the amount of tokens that the model gets as context from the document/paragraph.
The DocumentService has new features to support the Ollama models:
private final String systemPrompt = "You're assisting with questions about
documents in a catalog.\n" + "Use the information from the DOCUMENTS section to provide accurate answers.\n" + "If unsure, simply state that you don't know.\n" + "\n" + "DOCUMENTS:\n" + "{documents}";
private final String ollamaPrompt = "You're assisting with questions about
documents in a catalog.\n" + "Use the information from the DOCUMENTS
section to provide accurate answers.\n" + "If unsure, simply state that you
don't know.\n \n" + " {prompt} \n \n" + "DOCUMENTS:\n" + "{documents}";
@Value("${embedding-token-limit:1000}")
private Integer embeddingTokenLimit;
@Value("${document-token-limit:1000}")
private Integer documentTokenLimit;
@Value("${spring.profiles.active:}")
private String activeProfile;Ollama supports only system prompts that require a new prompt that includes the user prompt in the {prompt} placeholder. The embeddingTokenLimit and the documentTokenLimit are now set in the application properties and can be adjusted for the different profiles. The activeProfile property gets the space-separated list of the profiles the application was started with.
public Long storeDocument(Document document) {
...
var aiDocuments = tikaDocuments.stream()
.flatMap(myDocument1 -> this.splitStringToTokenLimit(
myDocument1.getContent(), embeddingTokenLimit).stream()
.map(myStr -> new TikaDocumentAndContent(myDocument1, myStr)))
.map(myTikaRecord -> new org.springframework.ai.document.Document(
myTikaRecord.content(), myTikaRecord.document().getMetadata()))
.peek(myDocument1 -> myDocument1.getMetadata().put(ID,
myDocument.getId().toString()))
.peek(myDocument1 -> myDocument1.getMetadata()
.put(MetaData.DATATYPE, MetaData.DataType.DOCUMENT.toString()))
.toList();
...
}
public AiResult queryDocuments(SearchDto searchDto) {
...
Message systemMessage = switch (searchDto.getSearchType()) {
case SearchDto.SearchType.DOCUMENT ->
this.getSystemMessage(documentChunks,
this.documentTokenLimit, searchDto.getSearchString());
case SearchDto.SearchType.PARAGRAPH ->
this.getSystemMessage(mostSimilar.stream().toList(),
this.documentTokenLimit, searchDto.getSearchString());
...
};
private Message getSystemMessage(
String documentStr = this.cutStringToTokenLimit(
similarDocuments.stream().map(entry -> entry.getContent())
.filter(myStr -> myStr != null && !myStr.isBlank())
.collect(Collectors.joining("\n")), tokenLimit);
SystemPromptTemplate systemPromptTemplate = this.activeProfile
.contains("ollama") ? new SystemPromptTemplate(this.ollamaPrompt)
: new SystemPromptTemplate(this.systemPrompt);
Message systemMessage = systemPromptTemplate.createMessage(
Map.of("documents", documentStr, "prompt", prompt));
return systemMessage;
}The storeDocument(...) method now uses the embeddingTokenLimit of the properties file to limit the text chunk to create the embedding. The queryDocument(...) method now uses the documentTokenLimit of the properties file to limit the text chunk provided to the model for the generation.
The systemPromptTemplate checks the activeProfile property for the ollama profile and creates the SystemPromptTemplate that includes the question. The createMessage(...) method creates the AI Message and replaces the documents and prompt placeholders in the prompt string.
Conclusion
Spring AI works very well with Ollama. The model used in the Ollama Docker container was stable-beluga:13b. The only difference in the implementation was the changed dependencies and the missing user prompt for the Llama models, but that is a small fix.
Spring AI enables very similar implementations for external AI services like OpenAI and local AI services like Ollama-based models. That decouples the Java code from the AI model interfaces very well.
The performance of the Ollama models required a decrease of the document-token-limit from 2000 for OpenAI to 150 for Ollama without GPU acceleration. The quality of the AI Model answers has decreased accordingly. To run an Ollama model with parameters that will result in better quality with acceptable response times of the answers, a server with GPU acceleration is required.
For commercial/production use a model with an appropriate license is required. That is not the case for the beluga models: the falcon:40b model could be used.
Published at DZone with permission of Sven Loesekann. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments