Why Data Cleaning Is Failing Your ML Models – And What To Do About It
When it comes to achieving model accuracy, data cleaning alone is insufficient. Here’s why.
Join the DZone community and get the full member experience.
Join For FreePrecise endeavors must be done to exact standards in clean environments. Surgeons scrub in, rocket scientists work in clean rooms, and data scientists…well, we try our best.
We’ve all heard the platitude, “garbage in, garbage out,” so we spend most of our time doing the most tedious part of the job: data cleaning. Unfortunately, no matter how hard we scrub, poor data quality is often too pervasive and invasive for a quick shower.
Our research across the data stacks of more than 150 organizations shows an average of 70 impactful data incidents a year for every 1,000 tables in an environment. These incidents invade exploratory data analysis; they invade model training, and validation; and invade the model’s inference data post-deployment, creating drift.
Model accuracy doesn’t start or end with data cleaning in your notebook with the few tables you use to inform, train, and validate your model. It starts with the ETL pipeline and the instant you choose what to measure to solve your problem.
Let’s walk through a semi-hypothetical scenario that contains real examples we’ve seen in the wild to highlight some common failure points. We’ll then discuss how they can be avoided with an organizational commitment to high-quality data.
Imagine This
You’re a data scientist with a swagger working on a predictive model to optimize a fast-growing company’s digital marketing spend. After diligent data exploration, you import a few datasets into your Python notebook.
Exploratory Data Analysis
Because your company is dashboard crazy, and it’s easier than ever for the data engineering team to pipe in data to accommodate ad-hoc requests, the discovery was challenging. The data warehouse is a mess and devoid of semantic meaning.
Without clear data lineage, you wasted time merging and cleaning data after failing to notice a downstream table with far more data sources already combined. That stung almost as much as when you noticed you almost left out a key dataset, but you console yourself that even the greats make those mistakes from time to time.
Model Design
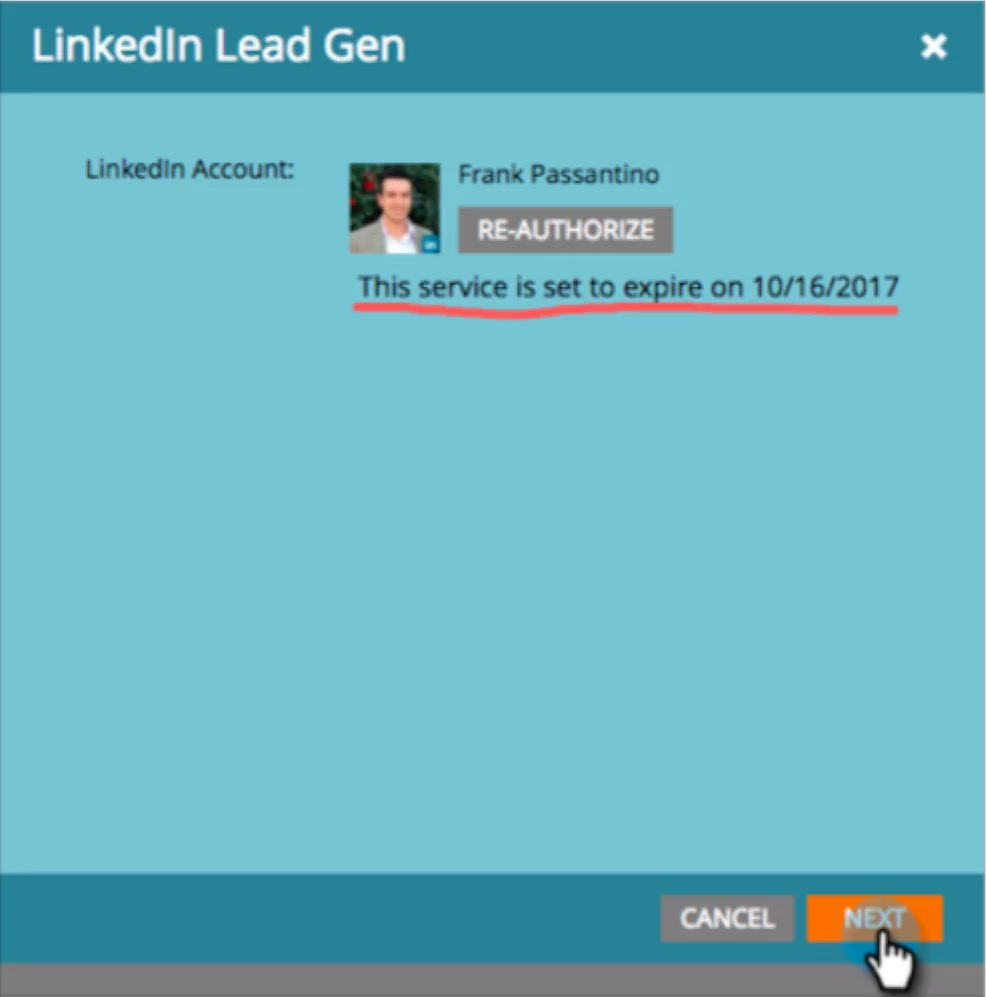
You see the LinkedIn ad click data has .1% NULLS, so you impute the value to the median of the feature column. That is neat and tidy in your notebook, but following model deployment, the integration between LinkedIn and the marketing automation platform wasn’t reauthorized. The NULLS in the production dataset have now jumped to 90%, causing this imputation to be much more frequent and based on a smaller, less accurate sample.
Your model also uses data inferred by another machine learning model for ad spend optimization that a former colleague built. Unfortunately, they built the model on thousands of temporary tables before leaving the company. It’s broken, on autopilot, and losing the company millions, but you don’t know that.
Model Training and Validation
You carefully separate out your holdout set to avoid contamination and ensure the data you use to validate your model will not overlap with the training data. Unbeknownst to you, the training data contains a table with aggregated visitor website data with columns that haven’t been updated in a month.
It turns out the marketing operations team upgraded to Google Analytics 4 to get ahead of the July 2023 deadline, which changed the data schema. This caused the automated ETL pipeline to spin up a completely new table, breaking the dependencies of the aggregated table. As a result, your training set doesn’t contain the last month of data, which included statistically significant shifts in browsing behavior and buying patterns as a result of the changing macroeconomic environment.

In both digital marketing and in data, the only constant is change: in this case, a changing schema messing with the pipelines on which your model depends.
Model Deployment
Your model is deployed and silently suffering from significant drift. Facebook changed how they delivered their data to every 12 hours instead of every 24. Your team’s ETLs were set to pick up data only once per day, so this meant that suddenly half of the campaign data that was being sent wasn’t getting processed or passed downstream, skewing their new user metrics away from “paid” and toward “organic.”
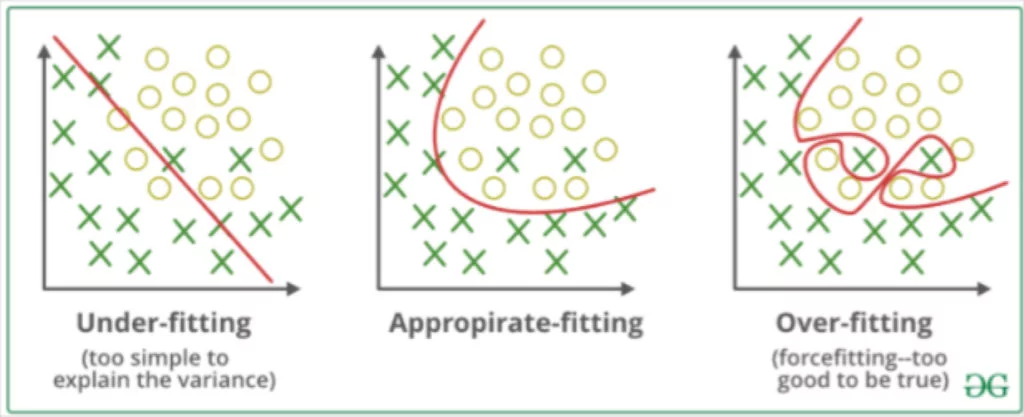
Image from Geeks for Geeks.
Model Review
All of these issues mean your predictive model had no impact on digital advertising performance. You’ve now lost the trust of the marketing team and senior executives. After all, they were skeptical in the first place. How could they trust a predictive black box when they see errors in their weekly reports and their dashboards crash twice a month?
Justifying additional headcount and investment in your team has now become much more difficult, even though the model’s failure was not your fault.
Does anything in this story sound familiar? While this specific tale might be a fabrication, stories like the one you just read are all too common among modern data teams. So, what can be done to avoid outcomes like this? Let’s take a look at how a commitment to data quality might help our data scientist yield better results.
Data Cleaning for the Modern Data Stack
A data scientist cannot and should not be responsible for cleaning every table in the data warehouse on a continuous basis. However, we do need to partner with our data engineering colleagues to create an environment fit for data science.
Just like a chef understands the supply chain for her ingredients, we should understand the supply chain of our data. Every organization has a different mix of data sources, and each one runs its pipelines slightly differently.
Some pipe everything into a central data warehouse or lake, while others operate separate environments for raw and prepared data with a layer of analytical engineers in between. Most can be better at clearing out legacy datasets.
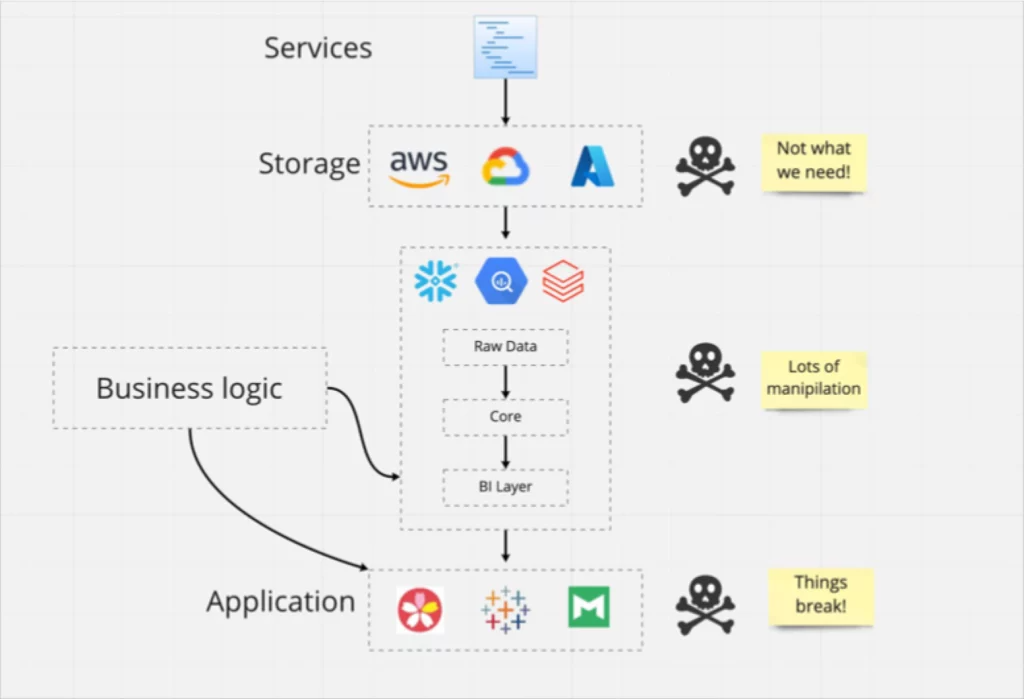
In addition to thinking at the dataset level with the traditional 6 dimensions of data quality (accuracy, completeness, consistency, timeliness, validity, and uniqueness), it’s time to start thinking at the pipeline level around data freshness, volume, schema, and distribution anomalies.
You can do this by building your own anomaly detectors (here’s a three-part series that shows how) or by leveraging a commercial data observability solution.
Monitoring for anomalies in the volume of data being ingested by your pipelines can ensure your model is always ingesting the minimum number of samples it needs to predict outcomes with high accuracy.
Gartner Hype Cycle for Data Management 2022
The advantage of a commercial solution is that instead of constantly updating and adjusting your custom monitor thresholds, you can count on a baseline of coverage across all data assets the minute they’re added while also being able to add custom monitoring rules whenever necessary.
Monitoring all your production pipelines and tables will not only make your job easier — it will also make your models more accurate.
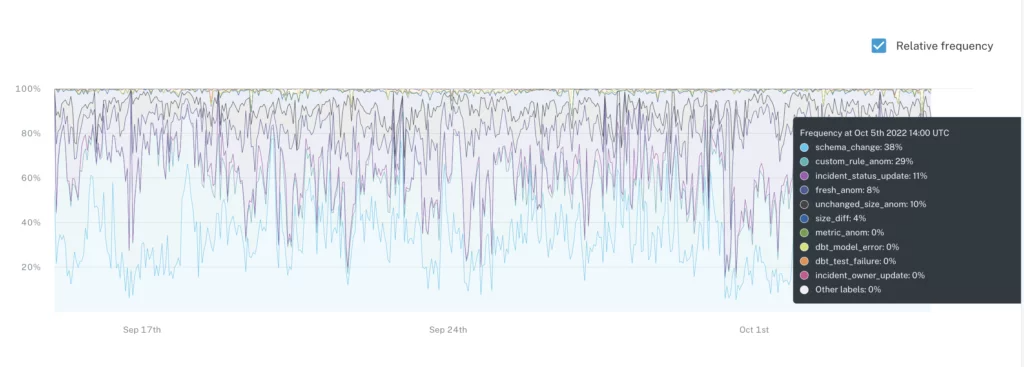
For example, by monitoring the distributions of values in the data, you can quickly see these ranges for the dataset rather than having to manually conduct multiple explorations and analyses to answer questions like the historical unique percentage. These monitors could also alert you to sudden changes in the proportion of each data class, as we saw in the Facebook example.
Monitoring for anomalies in the volume of data being ingested by your pipelines can ensure your model is always ingesting the minimum number of samples it needs to predict outcomes with high accuracy.
Data observability solutions also include data lineage and light cataloging features that can help during the discovery and exploratory data analysis process by surfacing relationships between objects and identifying related incidents.
 Data lineage within a data observability platform showing table dependencies.
Data lineage within a data observability platform showing table dependencies.
With a clean data environment, you can return your focus to creating precise, trusted ML models that drive business value.
This article was co-written with Ryan Kearns, data scientist at Monte Carlo, and Elor Arieli, Ph.D., data science lead at Monte Carlo.
Published at DZone with permission of Lior Gavish. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments